
Downloading Recordings from a Project Backup
This article goes through the steps to download raw recordings from Arbimon using the project backup. You can download your raw recordings using the recordings.csv file from your project backup. Files are downloaded as .flac files (an audio file type with lossless compression).
Please make sure you have enough space on your computer or external hard drive to download all the recordings. Each file is typically 3-4mb, and you can use the chart below to estimate your download size based on the number of recordings in your project.
| Number of Recordings | Lower Limit | Upper Limit |
| 1 recording | 3 MB | 4 MB |
| 10 | 30 MB | 40 MB |
| 100 | 300 MB | 400 MB |
| 1,000 | 3 GB | 4 GB |
| 10,000 | 30 GB | 40 GB |
| 100,000 | 300 GB | 400 GB |
| 1,000,000 | 3 TB | 4 TB |
Please note this will be done in your computer's terminal and requires Python to be downloaded (instructions on how to do this are provided in the steps below).
For Mac:
To open a terminal, go to spotlight search, type 'terminal' and click on the Terminal app.

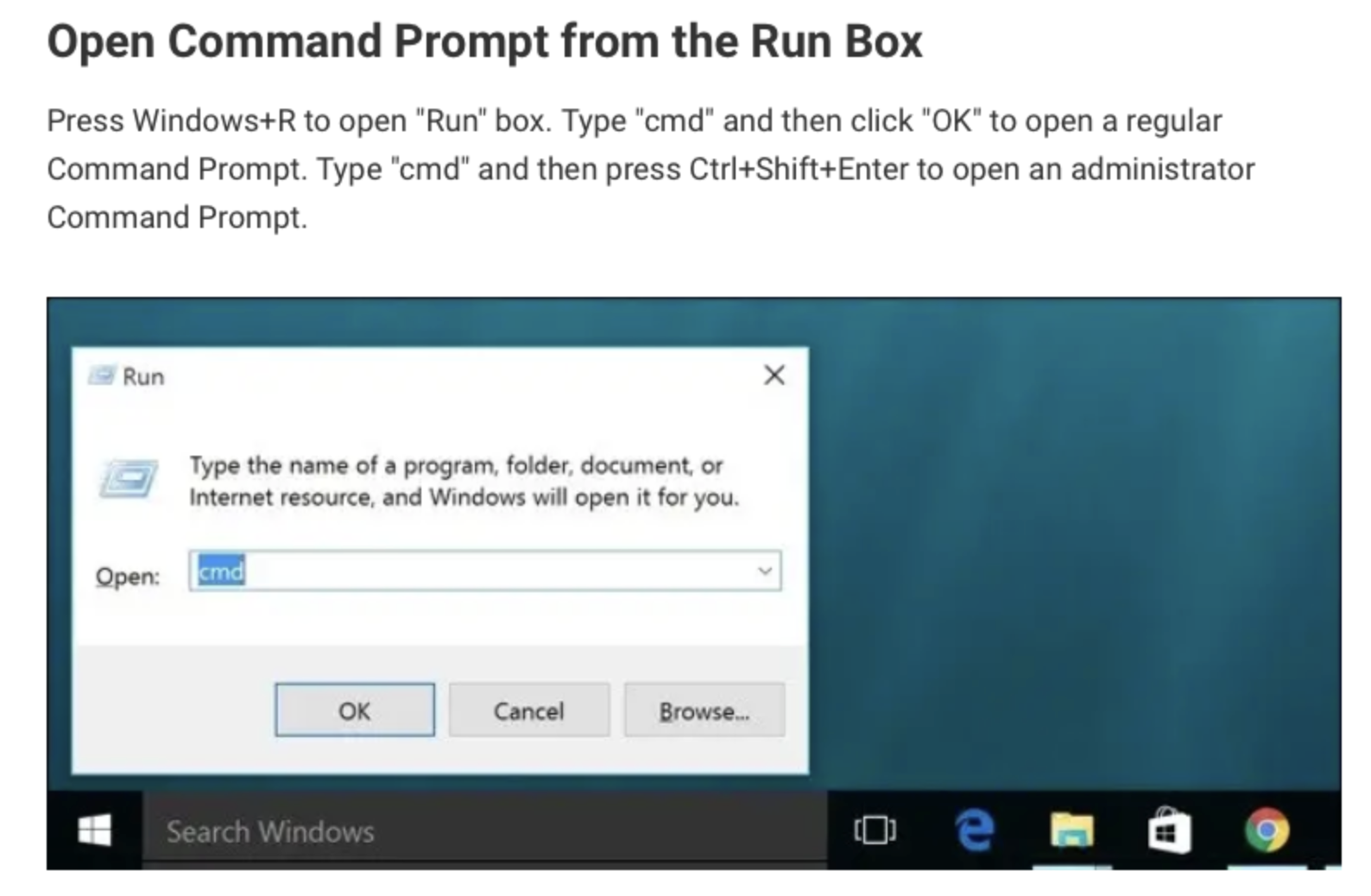
For Windows:
To open a terminal, open Run box, type 'cmd' and click ok (this will open a Command Prompt).
Install Python
Make sure you have Python (v3.x) installed on your computer.
For Mac:
MacOS and most of Linux OS come with Python pre-installed by default. To verify there's a Python installation on your macOS/Linux computer, open a new terminal and run the following command:
python3 --version
This should output the version of your Python installation.
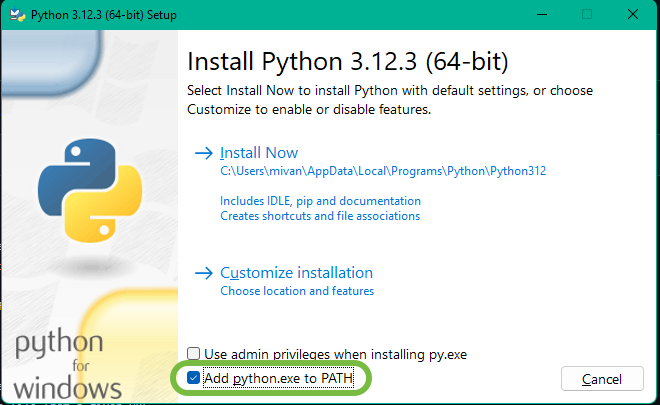
For Windows:
If your OS (e.g. Windows) doesn't come with pre-installed Python, check out the official documentation for instructions on how to download and install Python locally. When installing Python on Windows using the installer downloaded from the official documentation, make sure you click on Add python.exe to PATH before proceeding with the installation process:
After the installation process is completed, run the following command to verify Python installed successfully:
python --version
This should output the version of your Python installation.
Install 'pip'
Make sure you have Python's package manager pip installed. To check if you have pip installed on your macOS/Linux machine, run the following command -
For Mac:
pip3 --version
For Windows:
pip --version
This should output the pip version and a path to the pip bundle, as well as your local Python version. If you don't have pip installed, follow these instructions to get it up and running.
Install 'requests'
The script is quite simple and lightweight, but still it depends on an external package, called requests , that's not included in the Python standard library (i.e. there's a dependency). When there are external dependencies, we need to install these before running the code.
Install the requests package by opening your terminal and running the following command -
For Mac:
pip3 install requests
For Windows:
pip install requests
Download Script
Download the script for downloading the backup files from these following scripts
-
For recording files downloaded before July 3, 2024 (format YYMMDD):
download
download_files_v1.pyfrom this script -
For recording files downloaded on or after July 3, 2024 (format YYYYMMDD):
download
download_files_v2.pyfrom this script
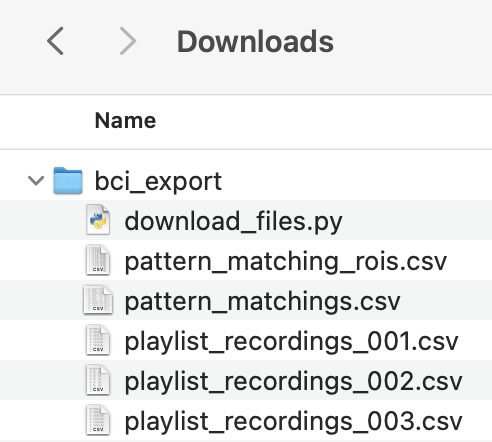
Put the script file into the folder containing the extracted files from your project backup (e.g. pattern_matchings.csv, recordings.csv, etc.)
Note: If you want to download your recordings to an external hard drive, make sure the export folder (with script inside it) is moved to that hard drive before running the script.
Run Script
Open a terminal window/command prompt and run this command to navigate to the project backup files.
cd <path-to-project-backup-folder>
Example: If the files from your backup are in folder named
bci_exportwhich is in your Downloads folder, runcd Downloads/bci_export.

Start the script by running the following command-
For Mac:
python3 download_files.py
For Windows:
python download_files.py
The script will start downloading the files and output its progress in the terminal:
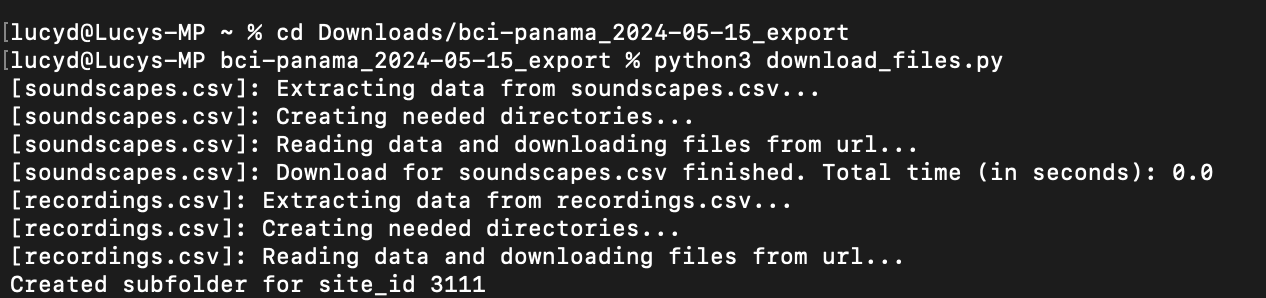
(Not recommended) If needed, you can stop the script by pressing ctrl + c. The script keeps track of which urls were processed, so if you run the script again, the download process will continue with the files that were still not downloaded.
The script reads the csv files in the current directory and downloads all files from your templates , soundscapes and recordings files. The downloaded files are grouped by site (if site_id is present in the csv file). The script should create a directory similar to this in your backup folder:
├── templates # files from templates.csv
├── soundscapes # files from soundscapes.csv
├── recordings # files from recordings.csv
│ ├── site_id
│ ├── site_id # recordings are grouped by site_id; each site has a separate folder
...
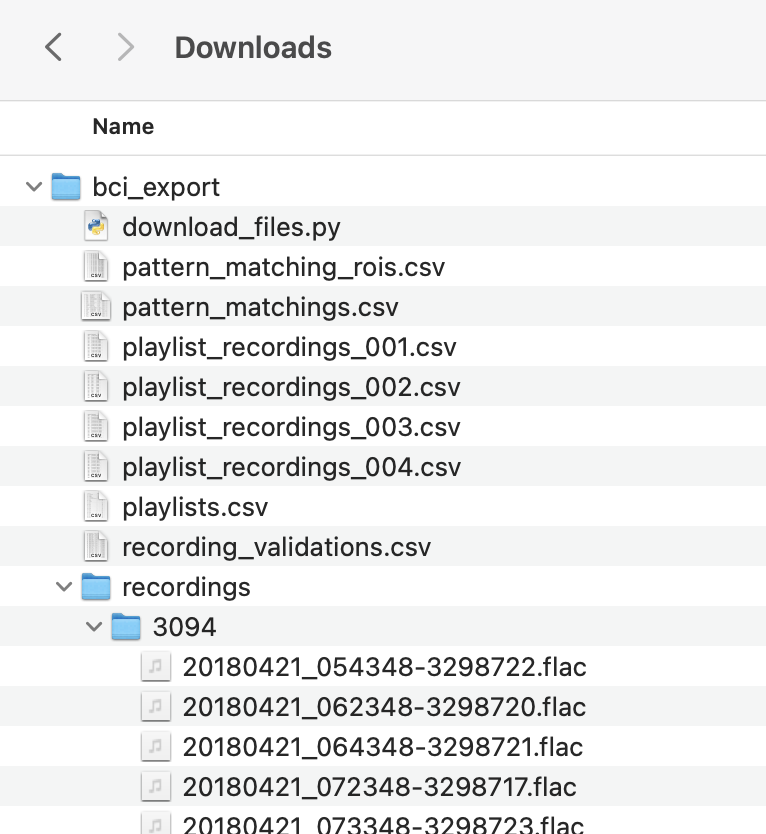
You can look up which site name correspond to the site ID (in the above screenshot, site ID=3094) in the sites.csv folder in your project backup.
Notes
- If your project contains a large amount of files, the script might take several days to finish. Please keep your computer on while the script is running.
- Do not manually edit the backup files until the download is complete, as the script relies on the original file structure. Feel free to create copies of the files in a separate folder for editing.
- Do not delete the autogenerated *.downloaded.txt files (they keep track of the download process, so if the files are deleted, the download process will start from the beginning if the script is re-run).
If you want to download only detected part of recordings from pattern matching result, you can follow this instruction.
If you run into difficulty with using the script, you can contact us (contact@arbimon.org) for further assistance.